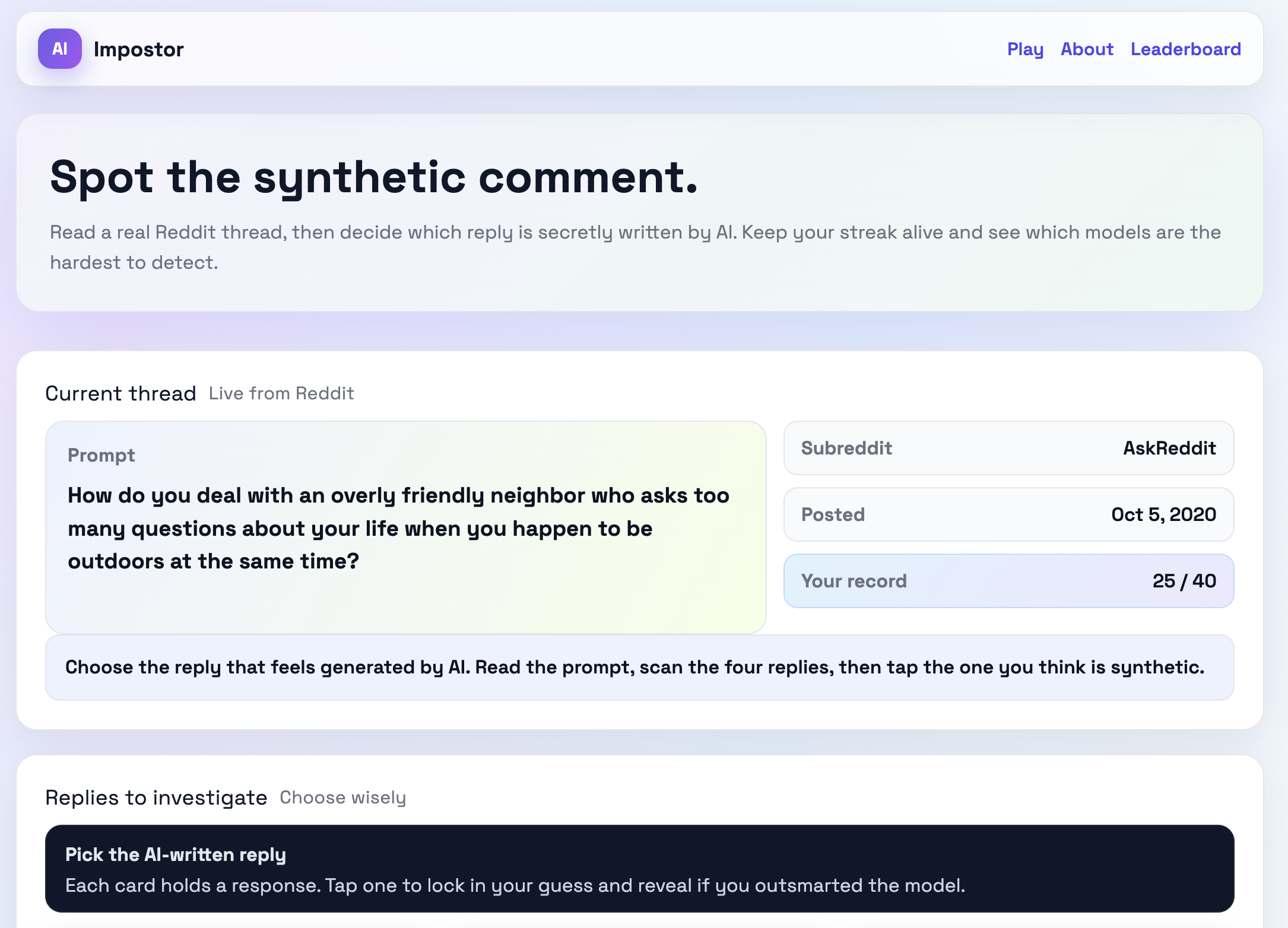
Check out the project: AI Impostor Site
Introduction
This project started out as a question; could the average internet user differentiate AI-generated comments from human generated comments?
I have seen plenty of comments on various forums claiming that AI-generated comments were easy to spot. I was skeptical of this claim. So, I decided to build a project to put it to the test.
The idea
At first, I thought it would be interesting to generate a real-time game where you were pitted randomly against another human or an LLM. The game would essentially be a head-to-head Turing test where you would convers through a chat interface with your “opponent” for some set amount of time. At the end of the time, you would need to guess whether your opponent was a bot or a human.
This presented numerous challenges both technical and non-technical. For example,
- The site would need enough users that there would always be someone else to chat with
- The speed of the response would give away whether the user was human or not
- I have never built anything close to a real-time chat interface and had no idea how to start
Finally, I limited the scope considerably. Instead, I would scrape Reddit for questions and answers. For each question, I would also generate an AI-generated response. This would be a much more manageable project
The design
The data source
I was looking for the best data source to extract questions and comments. StackOverflow has a lot of good content that they make accessible for free; however, the material is generally pretty in-depth and often technical.
I wanted a source that would have broad appeal. The purpose of this project is to get as much engagment as possible.
So, I decided to look more into Reddit. Each Subreddit has their own rules and customs. I wanted to find a subreddit that was primarily text based as opposed to image based. AskReddit was the obvious choice. All posts are a question contained entirely in the post title. The comments are answers to this question. Images are not allowed.
The comments
I wanted to take the most highly rated comment for each post; however, a few edge cases needed to be addressed
- Some comments are far too long
Sometimes users will write comments that are dozens of sentences long. The ai-generated comments were never this long. So, this would always indicate that the novel-length comments were human generated. I added a filter to only retrieve comments under 1000 characters
- Some comments were too short
On the other hand, many comments are a single word. This does not give the user much to go off of. So, I also added a minimum filter of 10 characters.
The AI Comments
The next step of the process was to generate the AI comments. I didn’t want the AI to have access to any of the human-generate comments because I didn’t want to bias the LLM to a specific answer, so I only fed in the post title to the LLM prompt. The prompt is:
prompt = (
f'Reddit post title: "{post.title}"\n\n'
f'Write a **realistic, concise Reddit-style comment** in response. Your comment will be shown alongside real human comments.\n\n'
f'The goal is to make your comment indistinguishable from a human response.\n'
f'- Avoid emojis\n'
f'- Use natural tone and phrasing\n'
f'- Do not explain or introduce the comment\n'
f'- Output only the comment text (no preamble or formatting)\n'
f'- Decide whether you should answer genuinely, sarcastically, or some other style'
)
I tried to strike a blanace between providing enough context to generate reasonable responses without hardcoding rules specifically to fool humans.
This all happens offline and a json file is generated with the responses. This json file is the same for all users of the site and is only updated when I extract additional posts/comments.
The AI Model
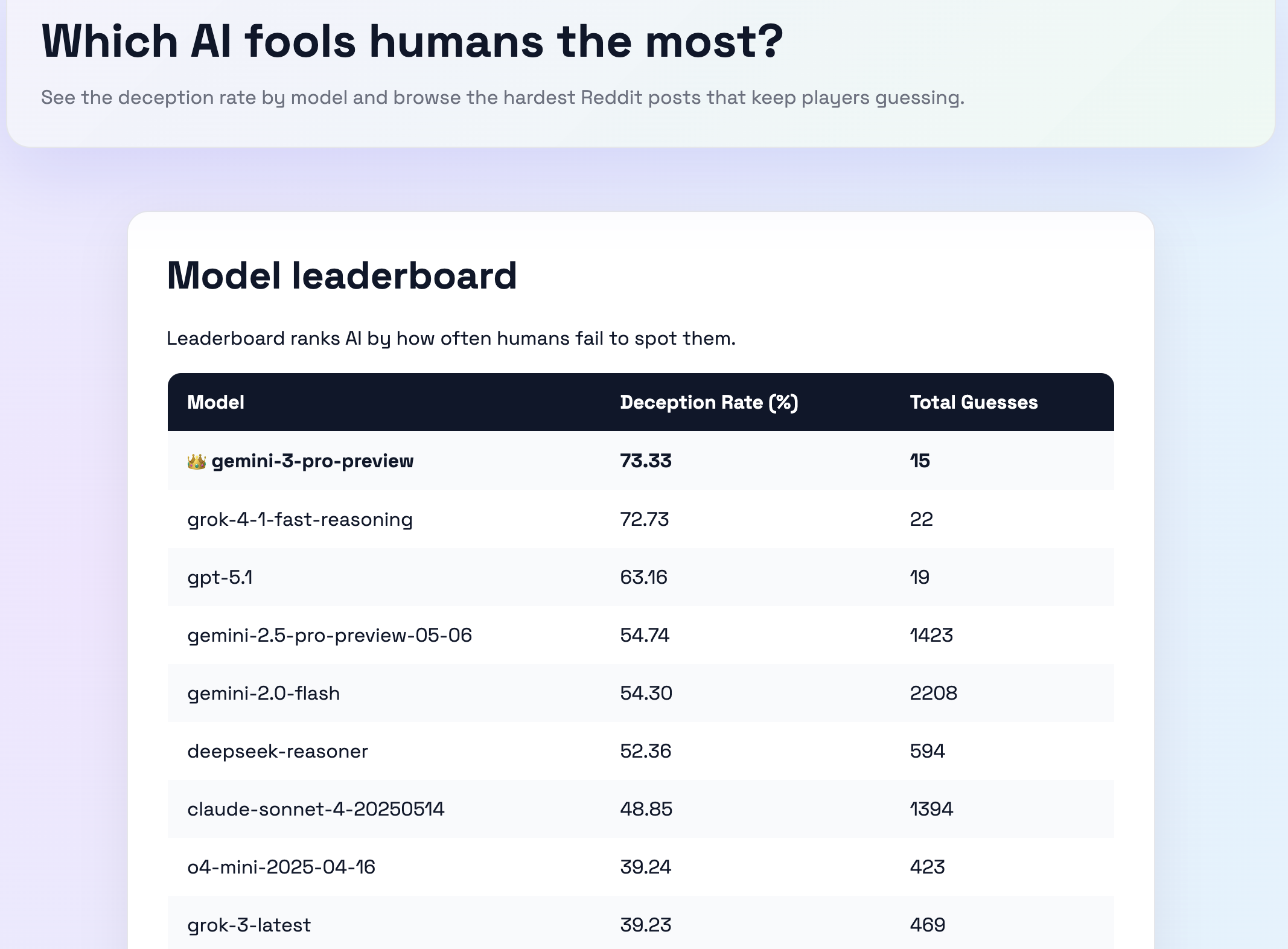
The next questions was which LLM model should we use to generate these comments? This was when I had the idea to try several different models. This has the added benefit of giving us a comparison point to see which LLMs are better than others at “blending in”.
To do this, we would just need to track which ai-generated comment was generated by which model. Then, we can track the accuracy of users’ guesses broken down by which model created that specific comment. That would allow us to create a cool leaderboard page by model.
Hosting
For a previous project I had used Render’s free tier for a web app. So, I would have to pay if I used Render again. I found PythonAnywhere(Referral Code) and decided to give that a try. It did end up requiring a paid subscription since I needed a database.
Conclusion
As of this post, the game has gotten over 9000 guesses. And a few trends seem clear:
- AI-generated comments can be difficult to identify
- There is a wide variance in identification rates by model type
- New LLMs are getting better at fooling humans