Creating SmartBookFinder
![]()
This blog post details the creation and architecture of my book recommendation site SmartBookFinder
The Motivation
I love reading, and one of the most exciting moments for me is finishing a book and deciding what to read next. However, I’ve struggled to find a recommendation platform that truly understands my preferences.
I primarily use Goodreads to keep track of the books I have read, my ratings, and my want to read list, but I have found their book recommendations to be underwhelming.
Since I had been using ChatGPT so much recently, and it had built up a large repository of memories and background on my projects, interests, and goals, I thought that asking ChatGPT for recommendations would be a good idea.
ChatGPT gave me a great response not only listing books that sounded intriguing but including a custom reason why it recommended each book personalized for me. This was already significantly better than any other book recommendation I had seen before. I started using ChatGPT for this purpose before deciding on every book. I didn’t always go with the book Chatgpt recommended, but it provided a good source to learn about books that I otherwise would never have heard about.
Since I was using Chatgpt so much for this purpose, I wanted to streamline the process and make it available to others. I set out to create a basic chatgpt wrapper. This resulted in a single page where users would fill out some basic information and a wall of text would be output, hopefully, with some book titles.
I enjoyed this process so much that I just kept adding features. The rest of this post details building those features along with my future plans for the site.
The Book Recommendations
This is the bread and butter of the site – the whole reason I initially created it. Over time, the book recommendations have grown to live in multiple places each with slightly different purpose or methodology for how books are recommended.
Reader Profile
The reader profile was the initial scope of SmartBookFinder. This is a section where users enter some data points about their personality and reading habits.
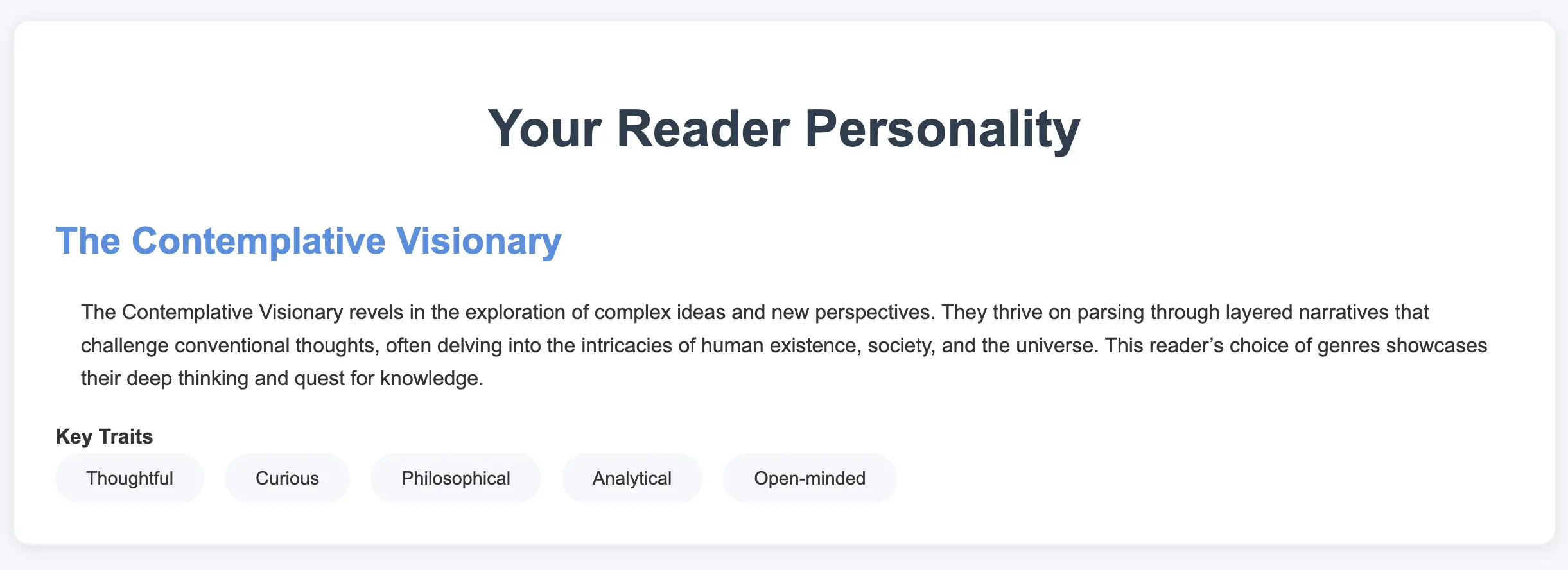
I then extract this input and put it into a standardized json message that can be sent to the ChatGPT API along with a prompt specifying the following:
You are an assistant generating personalized reader profiles based on user inputs. Analyze the given responses and create a **reader personality type** tailored to the user. Return the results in the following structured JSON format:
{
"personality_type": "<Name of the reader personality type (e.g., 'The Analytical Explorer')>",
"description": "<A brief description of this reader personality type, focusing on their reading habits, preferences, and motivations.>",
"traits": [
"<Trait 1 (e.g., Analytical)>",
"<Trait 2 (e.g., Curious)>",
"<Trait 3 (e.g., Reflective)>",
"<Trait 4 (e.g., Adventurous)>",
"<Trait 5 (e.g., Thoughtful)>"
],
"suggested_books": [
{
"title": "<Book Title 1>",
"author": "<Author Name 1>",
"description": "<Why this book is recommended for this reader personality type.>",
"reason": "<Why this book is recommended for this reader personality type.>"
},
...
I came to this format after a long time requesting the results as normal text and trying to parse the results. Receiving the results as structured json allows me to more easily parse different sections of the results.
Free form
I needed a way to search for books without altering my full reader profile. If one day I wanted books about the French Revolution, I didn’t want that preference to permanently affect all my future recommendations. To solve this, I built a simpler, one-time-use search tool, which became SmartBookFinder’s homepage because it:
- Had a lower barrier to entry than the reader profile
- Was more flexible than the reader profile
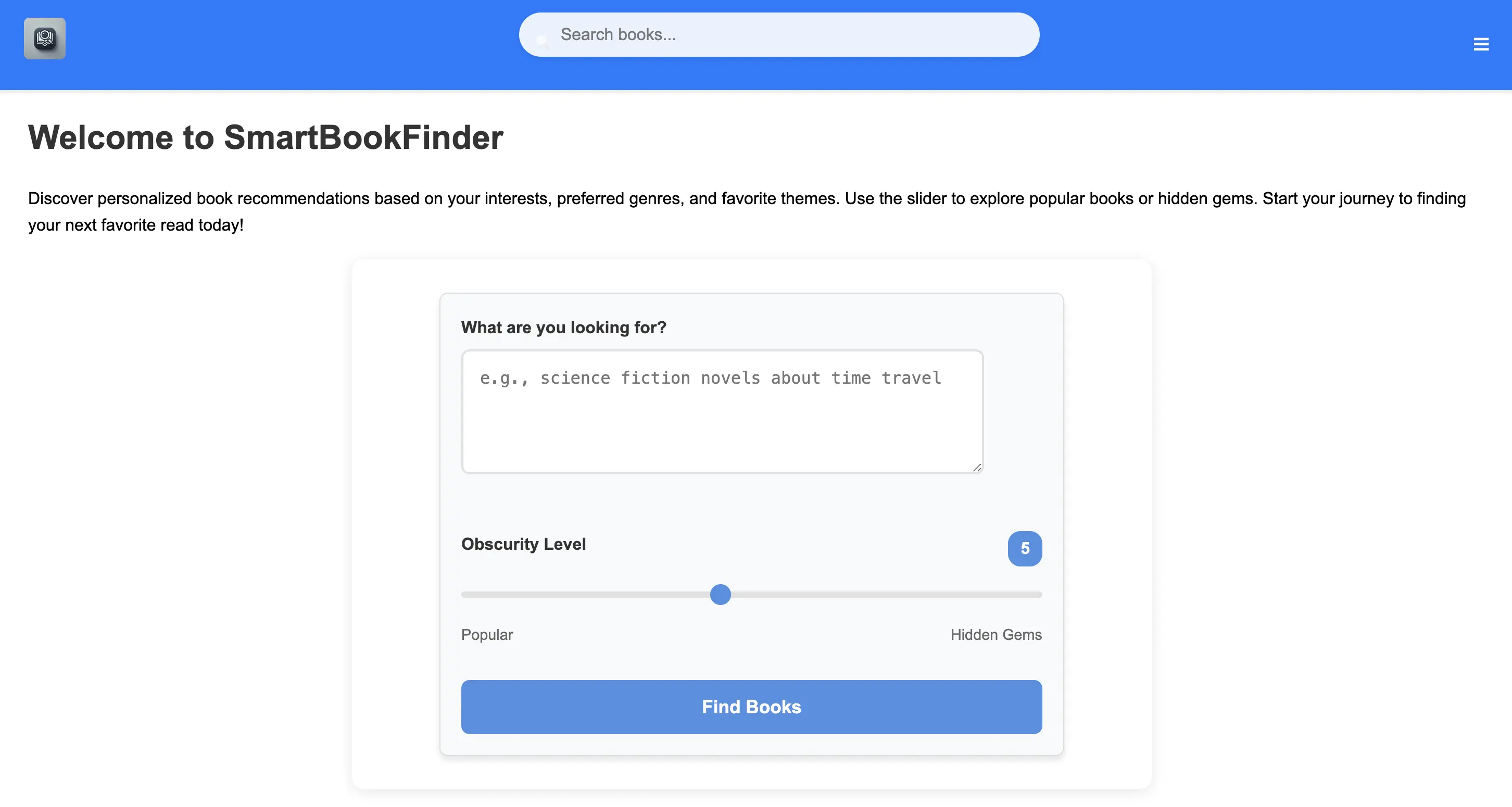
This is a simple flow that prompts the user for any kind of book preference. This prompt is then sent to the chatgpt API. Similarly to the reader profile section, the results are returned in json.
For each book returned , we can query the relevant metadata to construct the book card. This metadata includes things like the book thumbnail, description, and amazon link.
Login Functionality
The initial version of SmartBookFinder didn’t include user accounts. This worked fine for generating book recommendations on the fly, but it quickly became clear that users needed a way to save their reading preferences and track which books they had already read. Without a login system, every visit required users to re-enter their reader profile, and there was no way to personalize recommendations over time.
To solve this, I integrated Flask-Login, a lightweight authentication library for Flask that handles user session management. Flask-Login made it easy to implement features like persistent user sessions, so readers can log in and have their preferences, past recommendations, and “want to read” lists stored. It also enabled personalized book recommendations by remembering which books a user has already read, helping to refine future suggestions.
By adding login functionality, SmartBookFinder became a more personalized and interactive experience, allowing users to build their own evolving reading profiles rather than starting from scratch each visit.
Database
This login functionality meant a database was now required to persist user data across sessions.
User
The first thing I needed to do was create a user table along with a corresponding user class. This is what is created when a user actually registers for an account on SmartBookFinder. To ensure security, I store the password hash and don’t persist the actual password anywhere.
We extend flask-login’s default UserMixin class which provides some common authentication related methods. From there, we set up the logic to create the password hash and implement logic to check the password when a user attempts to login.
class User(UserMixin, db.Model):
__tablename__ = 'user'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(150), unique=True, nullable=False)
email = db.Column(db.String(150), unique=True, nullable=False)
password_hash = db.Column(db.String(200), nullable=False)
read_books = db.relationship('UserBook', back_populates='user')
def set_password(self, password):
from werkzeug.security import generate_password_hash
self.password_hash = generate_password_hash(password, method='pbkdf2:sha256')
def check_password(self, password):
from werkzeug.security import check_password_hash
return check_password_hash(self.password_hash, password)
read_books establishes a relationship with a separate table called user_books
that stores books for each user that they want to read, have already read,
or are recommended for them.
User_books
read_books = db.relationship('UserBook', back_populates='user') establishes
this relationship. It then checks user_books for any foreign key referencing
the user table. In this case, user_books has a foreign key on user_id, so
it knows that this is the join path.
class UserBook(db.Model):
__tablename__ = 'user_books'
id = db.Column(db.Integer, primary_key=True)
user_id = db.Column(db.Integer, db.ForeignKey('user.id'), nullable=False)
book_isbn = db.Column(db.String(13), db.ForeignKey('book.isbn'), nullable=False)
rating = db.Column(db.String(13), nullable=True)
status = db.Column(db.String(20), nullable=False, default="want_to_read")
timestamp = db.Column(db.DateTime, default=db.func.current_timestamp())
user = db.relationship('User', back_populates='read_books')
book = db.relationship('Book', back_populates='read_by_users')
Books
Since we now have a database, it makes sense to store book metadata locally rather than relying on API calls for every request.
Advantages of storing book metadata:
- Faster page loading – Data retrieval is quicker than making external API calls.
- Reduced reliance on third-party APIs – Avoids rate limits and potential service disruptions.
- Better data control – Enables more advanced querying, recommendations, and analytics.
Key Features:
- ISBN as Primary Key – Ensures uniqueness for each book.
- Title & Author – Essential metadata for display and searching.
- Description – Stores book summaries for a richer user experience.
- Published Date – Helps users find books based on release year.
- Page Count – Provides additional metadata for users looking at book length.
- Thumbnail – Stores cover image URLs for a more visually engaging UI.
- Categories – Allows for book organization and filtering.
- User Relationship – Links to user interactions, tracking books read, rated, or added to wishlists.
By storing book metadata, SmartBookFinder can improve performance, enhance personalization, and expand functionality in future updates.
Site Architecture
SmartBookFinder is designed with a simple yet scalable architecture, ensuring fast performance, easy maintainability, and flexibility for future enhancements.
Technology Stack
- Frontend: HTML, CSS, JavaScript (Jinja templating for dynamic content)
- Backend: Flask (Python)
- Database: PostgreSQL (Hosted via Render)
- Hosting & Deployment: Render (Handles both the web app and database)
- Caching & Performance: Future plans to integrate Redis or a CDN for speed improvements
Request Flow
- User Requests a Page
- Requests are routed through
app.py, which determines the appropriate response. - Pages are rendered using Flask templates (Jinja2).
- Requests are routed through
- Database Queries
- Book information and user interactions are stored in PostgreSQL.
- Queries are managed using SQLAlchemy for ORM-based interactions.
- AI-Powered Book Recommendations
- When a user searches for books, the backend:
- Processes input
- Calls OpenAI to generate personalized recommendations
- Fetches metadata from Google Books API
- Stores book data in the database for caching and future searches
- When a user searches for books, the backend:
- User Data & Authentication
- Users can log in, track books, and save preferences.
- Authentication is handled with Flask-Login and password hashing.
Hosting
Choosing the right hosting solution has always been a challenge for me. It often feels like a tradeoff between costly but simple options and cheap but complex setups.
After researching various platforms, I decided to go with Render. The main reason for this choice was ease of deployment—Render provided the simplest way to get my Slack app up and running, and I was able to do this under their free tier.
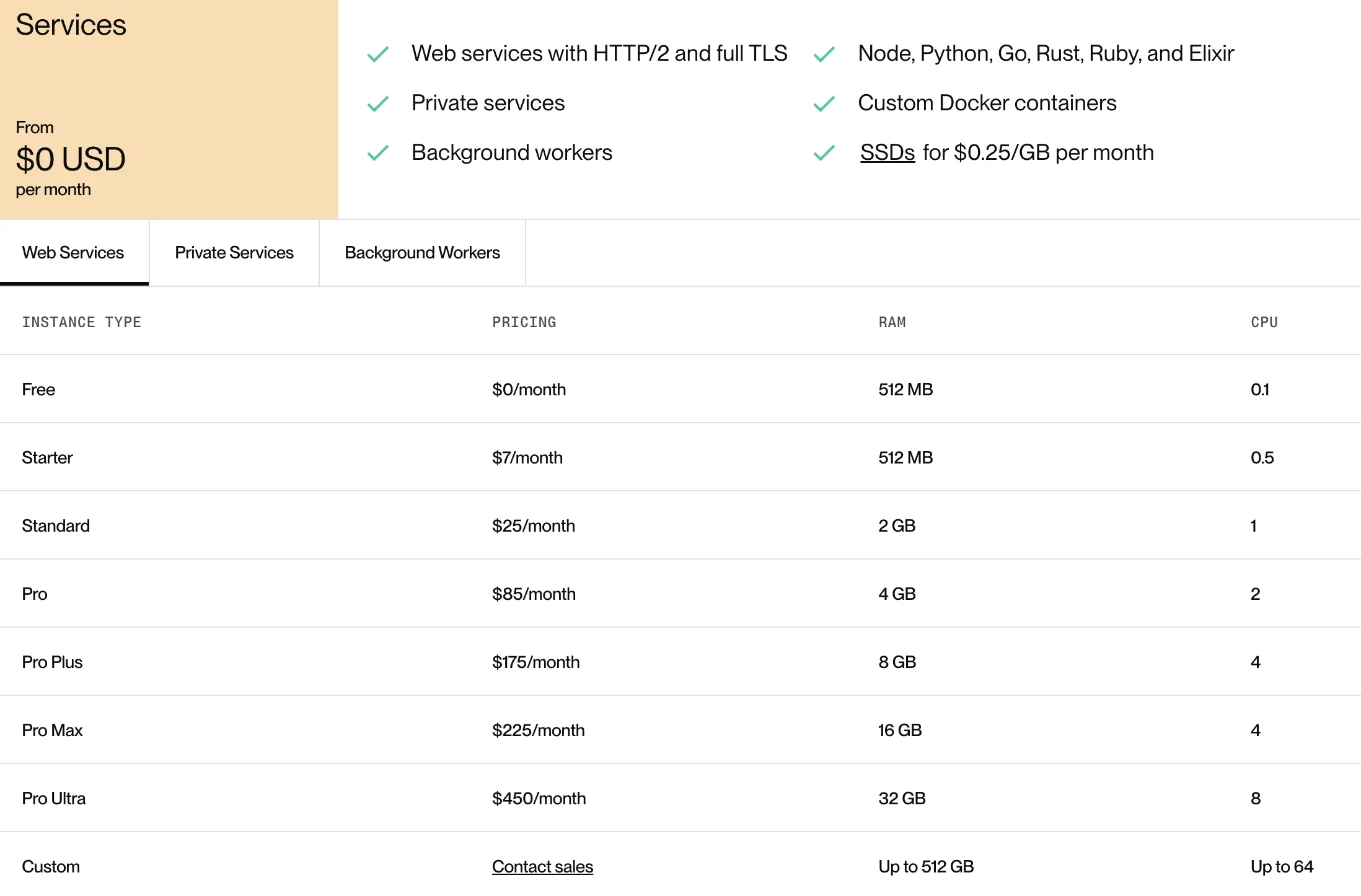
The Tradeoff: Free Tier Limitations
The free tier on Render does come with a notable downside: instances spin down after periods of inactivity. This means that if no one visits the site for a while, the next request can take up to a minute to load while the server starts back up.
Keeping My Site Always Online (For Free)
Since I prefer to keep costs low while avoiding long startup delays, I found a simple workaround—using a free uptime monitoring service like UptimeRobot. By setting up a ping every 15 minutes, I prevent my instance from ever going idle, keeping response times fast while still benefiting from Render’s free tier.
This setup strikes the right balance between affordability and performance, making Render a great choice for hosting SmartBookFinder.
Analytics
I am using Google Analytics to handle analytics. This just required adding a
JavaScript snippet to my base.html page. This provides an easy way to
monitor key metrics like:
Traffic & User Behavior
- Pageviews: Tracks how many times pages are visited.
- Unique Visitors: Helps understand how many distinct users are engaging with SmartBookFinder.
- Session Duration: Measures how long users stay on the site, indicating engagement levels.
- Bounce Rate: Tracks the percentage of visitors who leave after viewing only one page.
Acquisition & Sources
- Organic Search Traffic: Monitors how many users find SmartBookFinder through Google and other search engines.
- Referral Traffic: Tracks visitors coming from external links, like blogs, social media, or book forums.
- Social Media Traffic: Analyzes the impact of Twitter, Instagram, and other social platforms on visitor flow.
- Direct Traffic: Shows how many users type the URL directly into their browser.
User Engagement
- Click Tracking: Measures interactions like book recommendations clicked, searches performed, and external links followed.
- Conversion Rate: Tracks how many users mark books as “Want to Read” or interact with recommendations.
- Heatmaps & Scroll Depth: (Planned) Use additional tools like Hotjar to analyze how users navigate the site.
SEO Performance
- Top Landing Pages: Identifies which blog posts or book recommendation pages attract the most traffic.
- Keyword Performance: Uses Google Search Console to analyze which search terms drive visitors to the site.
- Exit Pages: Helps determine where users are dropping off and how to improve retention.
A/B Testing & Optimization
- Experimenting with Titles & Descriptions: Testing different blog post titles to see what attracts more clicks.
- Navigation Tweaks: Measuring how changes to menus and internal links affect engagement.
- Call-to-Action (CTA) Performance: Testing different CTA placements to encourage book interactions.
SEO Strategy for SmartBookFinder
My SEO strategy for SmartBookFinder focuses on increasing organic traffic by targeting relevant, low-competition keywords and optimizing for search engines. Here’s how I’m approaching it:
Keyword Research
I use Google Keyword Planner to find keywords with high search volume and low competition. These keywords help shape my blog posts, ensuring they align with what readers are actively searching for.
On-Page Optimization
Each blog post is optimized for SEO by:
- Including target keywords in the title, headings, and throughout the content.
- Writing compelling meta descriptions to improve click-through rates from search engine results.
- Using structured data (Schema.org markup) to enhance search engine understanding of my content.
- Optimizing images with descriptive alt text for accessibility and SEO benefits.
Internal Linking & Site Structure
I ensure strong internal linking between related blog posts and book recommendation pages. This improves navigation for both users and search engines, helping important pages rank higher.
Technical SEO Enhancements
- Fast Loading Speeds: The site is optimized for performance with clean code and efficient caching.
- Mobile Optimization: SmartBookFinder is fully responsive and works seamlessly across devices.
- Canonical URLs: Implemented to prevent duplicate content issues and consolidate SEO ranking power.
Content Strategy for Ranking
Beyond book recommendations, I’m producing:
- Listicles & guides (e.g., Best Books for Entrepreneurs, Hidden Sci-Fi Gems).
- Data-driven insights (Most Recommended Books on SmartBookFinder).
Lessons Learned
Marketing is the most important thing
I’ve spent a lot of time on this project. It was a great learning opportunity, but I’d be lying if I said I don’t get excited everytime a new user visits the site. For this, I need marketing, and it’s very difficult to stand out.
During development, I decided to take a look at other websites with similar functionality. There are a bunch. Many of these competitors look great and feel great. MeetNewBooks, for example, is one of my favorites. To compete with them, I need SmartBookFinder to be seen.
User-Friendly is more important than technically ideal
My first iteration of SmartBookFinder had individual book pages with the following
url structure, www.smartbookfinder.com/book/<isbn>. I thought this was a great
approach because each book would have a unique isbn, so there would be no risk
of books with the same title having conflicting URLs.
Unfortunately, I quickly noticed a much lower CTR for book pages than other pages. I believe this was due to the non-user-friendly, and almost suspicous-looking, urls consisting of only a number.
Recently, I have changed the url to www.smartbookfinder.com/book/<book-title>-<isbn>
to more accurately reflect what is on a given page in google search results. We will
see if this improves click through rates.
UI is much more difficult than I thought
I thought the UI and layout of pages would be an afterthought – I was dead wrong. This has taken up the majority of my time. Everytime I modify the size of a component on one page, it seems to break 5 other components on some different page.
I have started being more specific with my CSS component naming. Instead of a
generic class=container, I will do something like class=reader-profile-page-container.
That way I have more control over changing the look of just a single page instead
of dealing with unforeseen consequences reverberating across my entire site after
every edit.
Next Steps
Lean more into marketing
As I mentioned above, marketing is everything, and I want to see how far I can take SmartBookFinder. For this, I plan on focusing on
- Social Media Marketing: I have created an Instagram account and plan to start posting
- Reddit: I have also created a subreddit that I want to start a community on
- Improve SEO: This is a constant struggle that I enjoy working on. I want to continue blog posts and optimizing on page and technical SEO
Build out additional functionality
Building out additional functionality helps me provide more value to users, flex my technical chops, and it’s fun.
Integrating with Overdrive
This is my white whale. Overdrive is a platform that links with library accounts across the country to access free digital book rentals. My main goal is to allow users to sign up on SmartBookFinder and select their library. Then, I can use Overdrive’s API to show the Overdrive status for each book at the user’s specified library. I am currently applying for Overdrive API access.
Support synchronous book clubs
I think this would be a differentiator from many other platforms available today. I’m envisioning a community of book-lovers who can engage in live virtual book discussions. This requires a critical mass to work, so I plan on creating a waitlist until we reach a number of interested users that will make this possible.